
Introduction to Large Language Models
Language is important. It’s how we learn about the world (e.g. news, searching the web or Wikipedia), and also how we shape it (e.g. agreements, laws, or messages). Language is also how we connect and communicate — as people, and as groups and companies.
Despite the rapid evolution of software, computers remain limited in their ability to deal with language. Software is great at searching for exact matches in text, but often fails at more advanced uses of language — ones that humans employ on a daily basis.
There’s a clear need for more intelligent tools that better understand language.
Large Language Models
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.
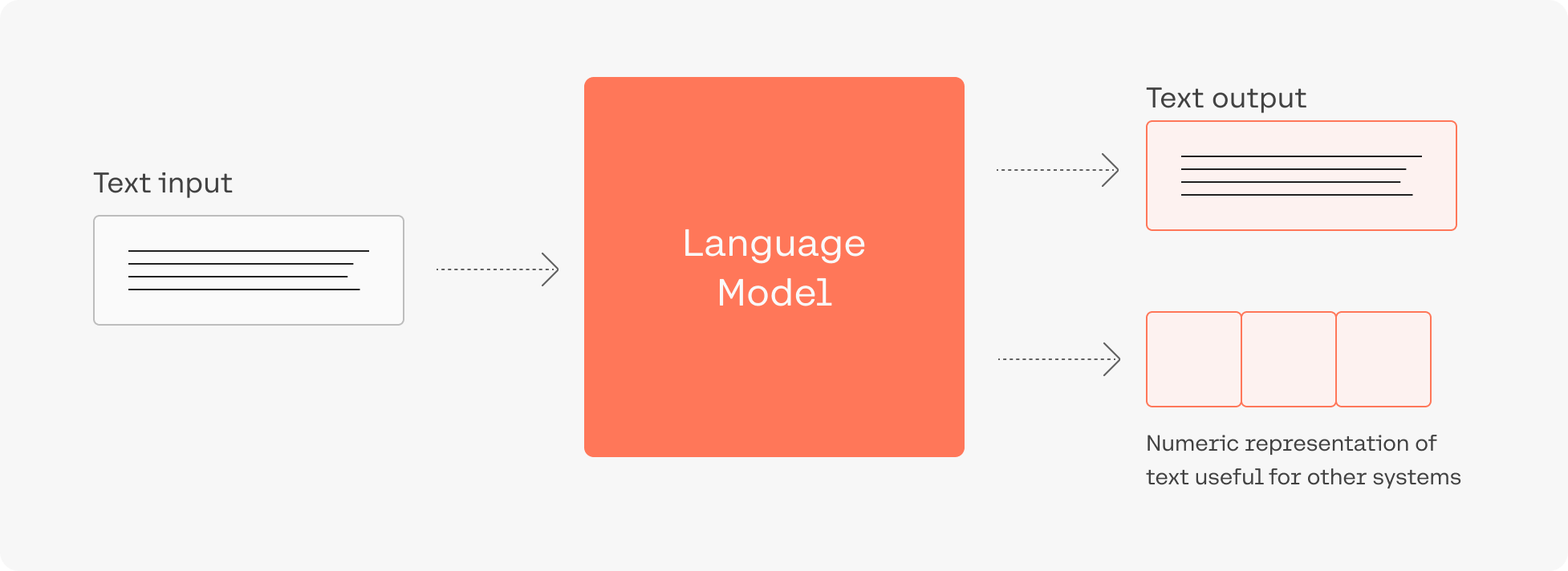
Large language models are computer programs that open new possibilities of text understanding and generation in software systems.
Consider this: adding language models to empower Google Search was noted as “representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search“. Microsoft also uses such models for every query in the Bing search engine.
Despite the utility of these models, training and deploying them effectively is resource intensive, requiring a large investment of data, compute, and engineering resources.
Updated about 1 month ago