An Overview of the Developer Playground
The Cohere Playground is a visual interface supporting two models:
It’s a great way to test our models for specific use cases without writing code; when you’re ready to start building, simply click View Code to get the underlying logic to add to your application.
Using the Playground
In the next few sections, we’ll walk through how to interact with both supported models via the Playground.
Chat
The Chat endpoint provides a response (i.e. language or code) to a prompt. You can use the Chat Playground to generate text or code, answer a question, or create content. It looks like this:

Your message goes in the Message... box at the bottom, and you can pass a message by hitting Enter or by clicking the Send button.
You can customize the model’s behavior with the System message, which is a prompt that guides the model as it generates output. You can learn more about how to craft an effective system message in our dedicated guide.
To customize further within the Playground, you can use the panel on the right:
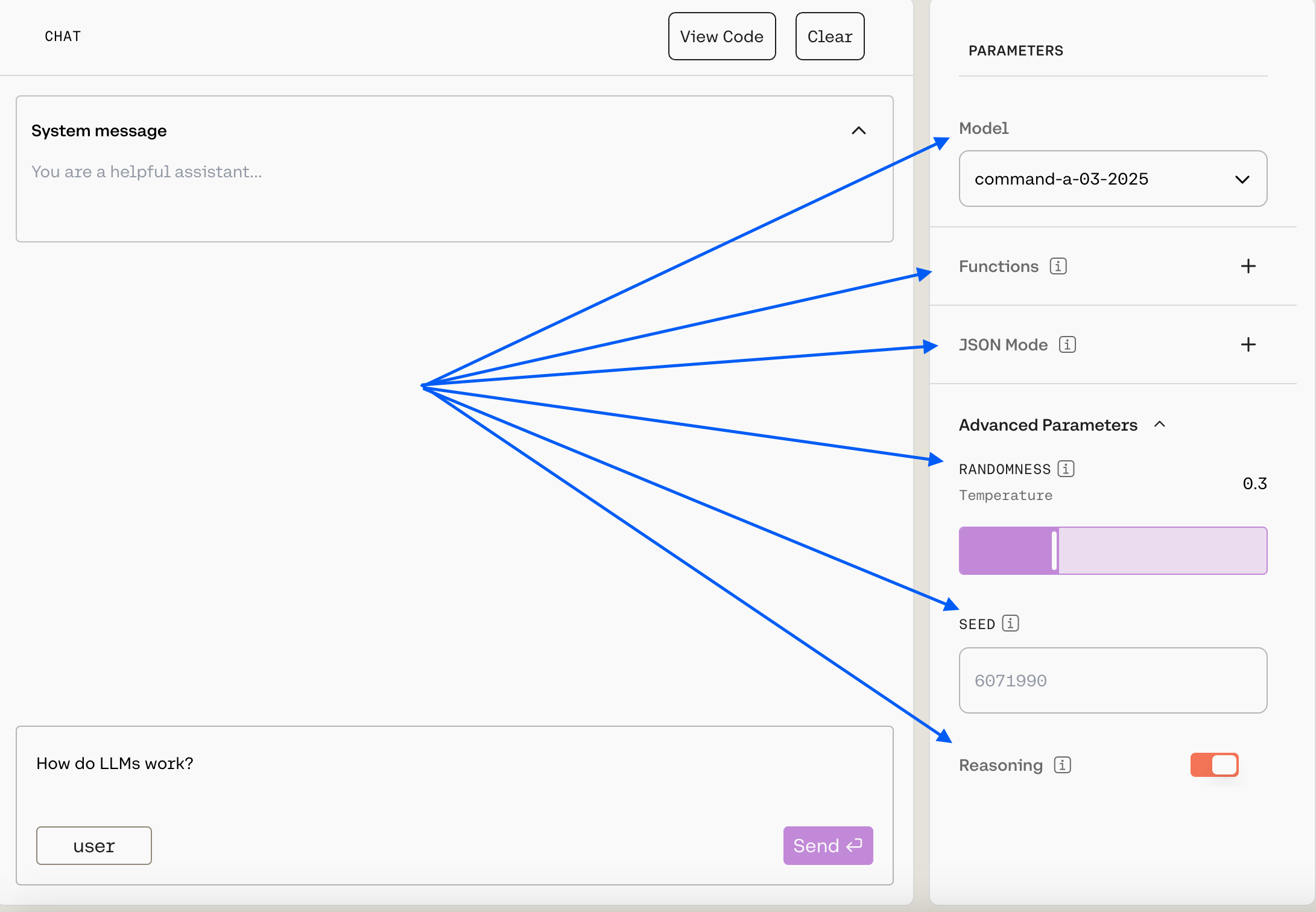
Here’s what’s available:
Model: Choose from a list of our generation models (we recommendcommand-a-03-2025, the default).Functions: Function calling allows developers to connect models to external functions like APIs, databases, etc., take actions in them, and return results for users to interact with. Learn more in tool use docs.JSON Mode: This is part of Cohere’s structured output functionality. When enabled, the model’s response will be a JSON object that matched the schema that you have supplied. Learn more in JSON mode.- Under
Advanced Parameters, you can customize thetemperatureandseed. A higher temperature will make the model more creative, while a lower temperature will make the model more focused and deterministic, and seed can help you keep outputs consistent. Learn more here. - Under
Advanced Parameters, you’ll also see the ability to turn on reasoning. This will cause the model to consider the implications of its response and provide a justification for its output. More information will be available as we continue to roll out this feature.
Embed
The Embed model enables users to create numerical representations for strings, which comes in handy for semantic search, topic modeling, classification tasks, and many other workflows. You can use the Embed Playground to test this functionality, and it looks like this:

To create embeddings through the Playground, you can either use Add input to feed the model your own strings, or you can use Upload a file. If you select Run, you’ll see the two-dimensional visualization of the strings in the OUTPUT box.
As with Chat, the Playground’s Embed model interface offers a side panel where you can further customize the model:

Here’s what’s available:
Model: Choose from a list of our embedding models (we recommendembed-english-v3.0, the default).Truncate: This allows you to specify how the API will handle inputs longer than the maximum token length.
Next Steps
As mentioned, once you’ve roughed out an idea you can use View Code to get the logic. If you want to explore further, check out our:
- Models page
- Text Generation docs
- Embeddings docs
- API reference
- Integrations page
- Cookbooks