
Playground Overview
What is the Playground?
The Cohere Playground is a visual interface for users to test Cohere large language models without writing a single line of code. To familiarize yourself with our endpoints, we recommend clicking the Generate or Calculate button on each endpoint page and observing the outputs. Use the Playground to test your use cases and when you're ready to start building, simply click Export Code to add Cohere's functionality to your application.
Using the Playground
Generate
Generate produces natural language text in response to an input prompt. As seen in the screenshot below, we supplied the model with a prompt, "Given a product and keywords, this program will generate exciting product descriptions. Here are some examples:" and gave two examples of a product and keywords. The bolded text was generated by the model.
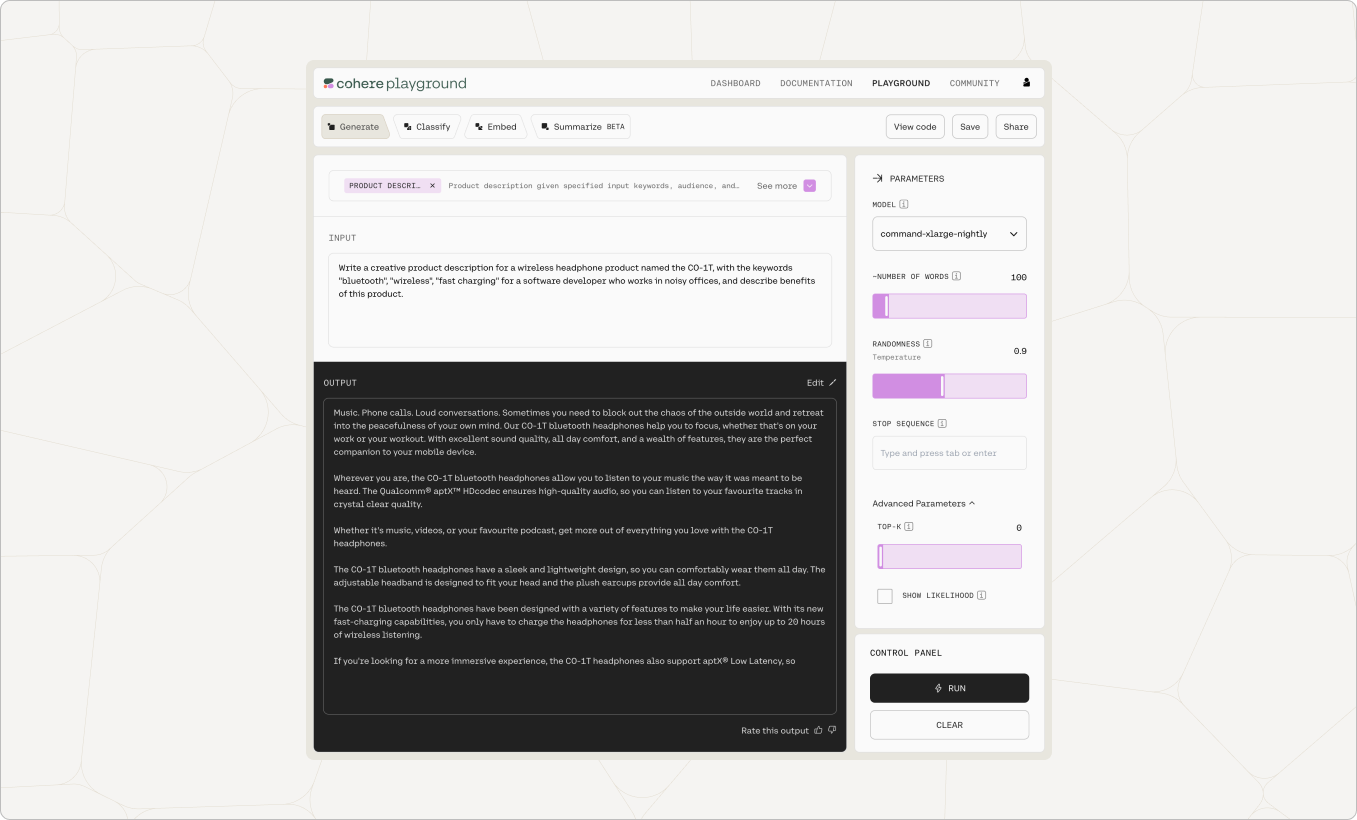
- To write inputs that produce the best results for your use case, read our Prompt Engineering guide.
- Try tinkering with different temperature and token-picking settings to alter the model's output behavior.
- To further improve your generations or to get the model to focus on generating text about a specific topic, try uploading a sample text to train the model. If you're interested in training a model, please submit a Full Access request from your Cohere Dashboard.
Try asking the model to do any of the following:
- Summarize a paragraph of text
- Generate SEO tags for a blog post
- Produce some questions for your next trivia night
- Provide ideas of what to do in your city this weekend
In each case, give the model a few examples your desired output.
Additionally, note the Show Likelihood button within Advanced Parameters. This feature outputs the likelihood that each token would be generated by the model in the given sequence, as well as the average log-likelihood of each token in the input. Token likelihoods can be retrieved from our Generate endpoint.
The log-likelihood is useful for evaluating model performance, especially when testing user-trained models. If you're interested in training a model, please submit a Full Access request from your Cohere Dashboard.
Embed
Using Embed in the Playground enables users to assign numerical representations to strings and visualize comparative meaning on a 2-dimensional plane. Phrases similar in meaning should ideally be closer together on this visualization. Add a couple of your own phrases and see if the Playground visualization feels accurate to you.
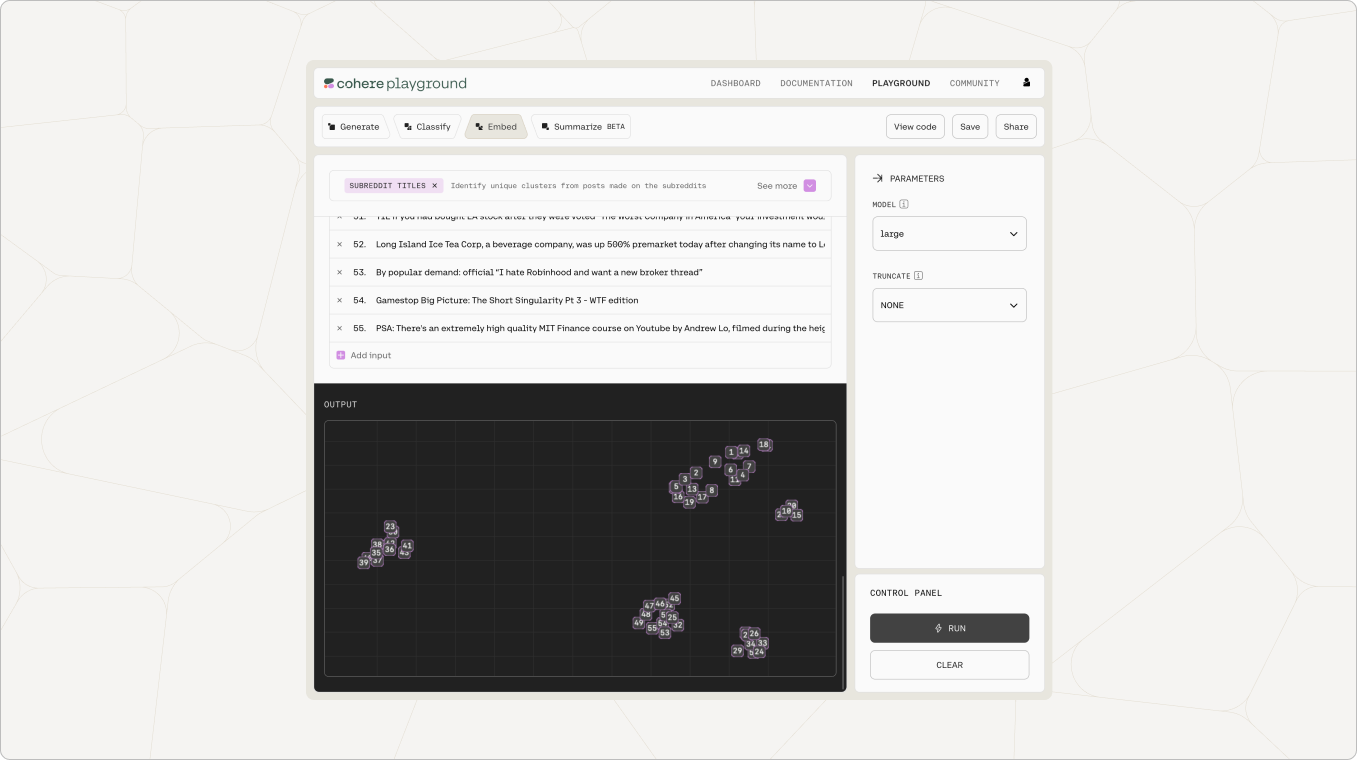
Cohere embeddings can be used to train a semantic classifier out of the box, saving users countless hours gathering data to train a model themselves.
Classify
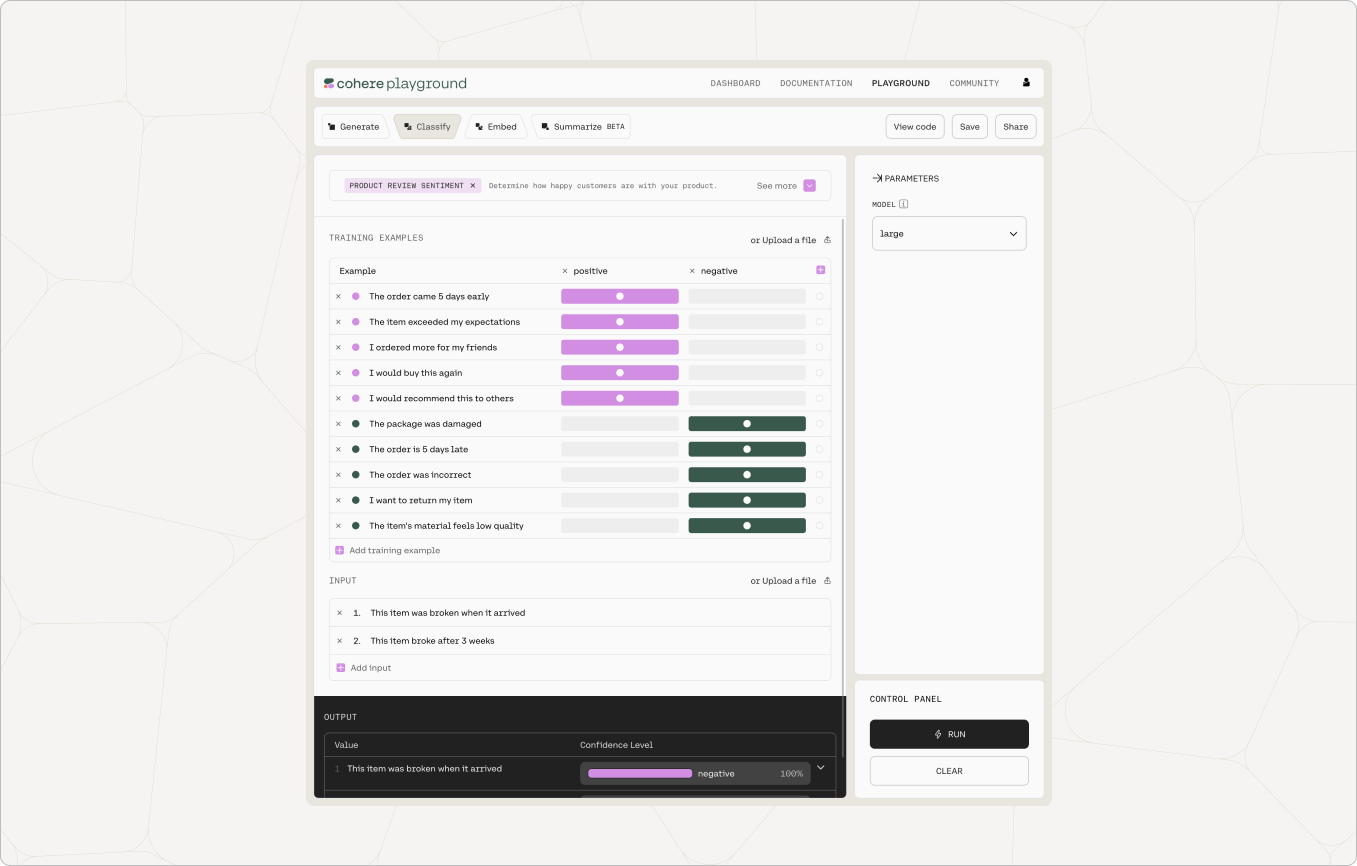
The Cohere Classify endpoint enables users to create a classifier from a few labeled examples.
Selecting the Right Model Size
Larger models are more capable of complex tasks but smaller models have faster response times and are less expensive. Here is a rough guideline for which model size to use for various tasks:
Generation models
command
The Command family of models are the most capable generative models, and can perform any task other models can with better results. They're well suited for challenging tasks including complex extraction, rewriting, question-answering, summarization, conversation, and brainstorming.
command-light
Command Light provides a great tradeoff between power and speed. Use this model to power tasks like generating marketing ad-copy, extracting key entities from text, or powering conversational agents.
Representation models
embed-english-v2.0
Embed is our most capable representation model and can perform any tasks other models can, with better results. The large model performs better at few-shot classification tasks in both single label and multi-label scenarios. Large embeddings have 4096 dimensions.
embed-english-light-v2.0
Embed Light is our fastest model, and has the lightest storage requirements. Small embeddings have 1024 dimensions.
embed-multilingual-v2.0
We currently have a single multilingual representation model available on out platform. The embeddings have 768 dimensions.
Updated 1 day ago