
Likelihood
Our models learn to model language by reading text scraped from the internet. Given a sentence, such as I like to bake cookies, the model is asked to repeatedly predict what the next token [?] is:
I [?]
I like [?]
I like to [?]
I like to bake [?]
I like to bake cookies
The model learns that the word to is quite likely to follow the word like in English, and that the word cookies is likely to follow the word bake.
Intuition
(NOTE: throughout we use "likelihood" as a shorthand for "mean token log likelihood". There is a such thing as likelihood in machine learning, but we're referring to the more specific mean token log likelihood.)
The mean log likelihood of a token can be thought of as a number (typically between -15 and 0) that quantifies a model's level of surprise that this token was used in a sentence. If a token has a low mean log likelihood, this indicates that the model did not expect this token to be used. Conversely, if a token has a high log likelihood, the model was confident that it would be used.
For our model, the likelihood of to in the sentence I like to is roughly -1.5. This is quite high, and means that the model was fairly confident that the tokens I like would be followed by the token to. Similarly, the likelihood of cookies in the sentence I like to bake cookies is roughly -3.5, a bit lower than the previous example. This makes intuitive sense, as brownies or cake would have also been reasonable options, but it's still quite high. However, if we change the sentence to I like to bake chairs then the likelihood of the token chairs is considerably lower, at around -14. This means the model is extremely surprised at its use within the sentence.
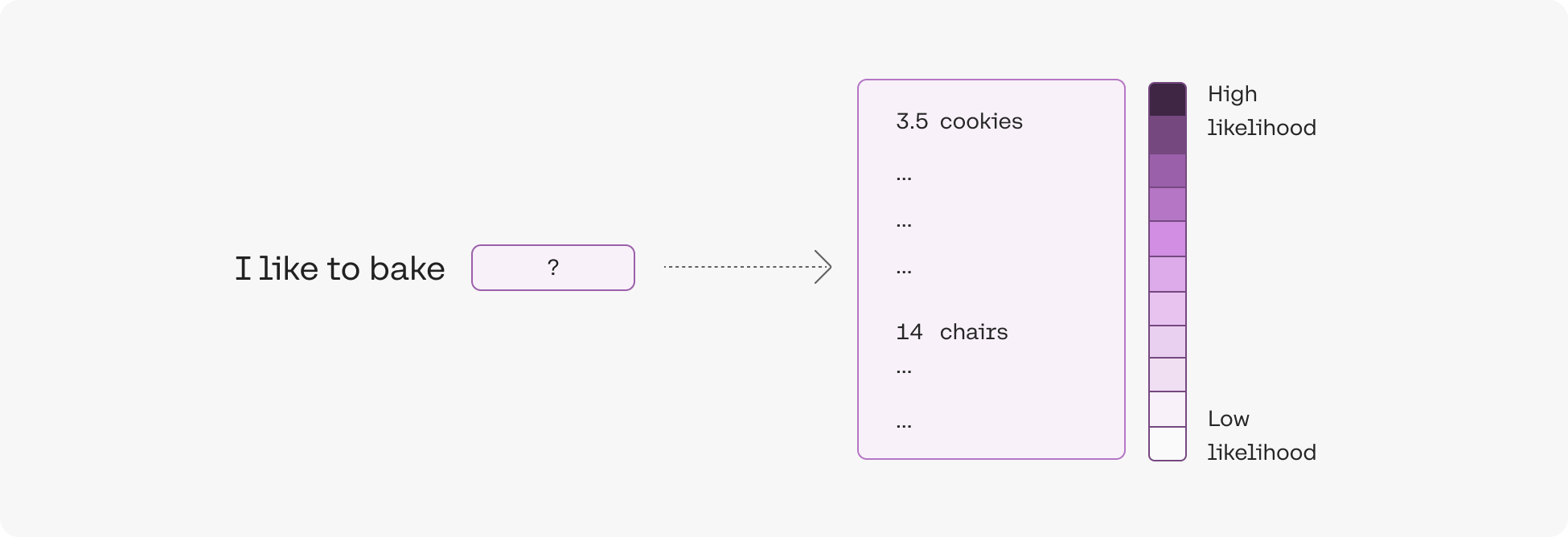
An illustration of the likelihood of the two tokens discussed.
Updated about 1 month ago